Hope is not a forecast.
You get fired for not seeing it coming." George Storm rebuilds the CRO forecast with regime-weighted modelling and a per-metric mitigation playbook.
"You don't get fired for missing the number. You get fired for not seeing it coming."
That's the new bar for the CRO seat, and it's the reason this piece exists.
I've been stress-testing my forecasting model because there are so many market conditions to consider nowadays. The model said clearing our €10M commit was a high-confidence outcome, with a probability in the high-80s (based on a Monte Carlo analysis). Six weeks later, I went back with the recalibrated number: central forecast €8.6M. Below the commit. Same business. Different models.
Nothing changed in the company. What changed was that I stopped letting my model lie to me. And the version that doesn't lie says the work of the CRO seat has to change with it.
This piece is about four things, in order:
- A forecasting model that takes external macro pressure seriously instead of assuming it away.
- The discipline of telling boards and CEOs what the model actually says, not what we hope it says.
- A method for working out which of your metrics each kind of market shock will hit.
- A per-metric mitigation playbook that turns the analysis into action before the quarter you're forecasting is the quarter you're losing.
This is also, by the end, an argument about what the CRO role is becoming. Because if you accept that the four things above are now part of the job, the seat is not the same seat it was three years ago. And the people sitting in it have to change with it, or they get replaced by people who already have.
The model that didn't survive contact with reality
Like most CROs at our stage, I'd inherited a forecasting practice that was basically pipeline × stage probability × historical win rate, dressed up in a Monte Carlo wrapper to feel rigorous.
The Monte Carlo bit was the problem. It made the output look defensible while the inputs assumed away the thing I was actually worried about.
The model treated three risks as independent shocks: deal slip from acquisitions, deal slip from leadership turnover, deal slip from budget freezes. Each got its own probability. The simulation summed them up. P(≥€10M) came out in the high-80s because the chance of all three firing simultaneously was vanishingly small.
It took looking at five live deals, every one of them paused for one of those three reasons, to realise the math was wrong. The three "independent" shocks were the same shock. When the macro turns, M&A accelerates, executives turn over, and budgets freeze. They share a driver. They are not independent.
That's where the hope-is-not-a-strategy problem starts. The old model didn't fail because of bad inputs. It failed because it was structured to give me the answer I wanted. Three risks, low joint probability, comfortable headline number, board reassured, CRO sleeps. The mechanism of self-deception was the model itself. And I was the one who built it.
So I rebuilt it.
The framework
Forward ARR = (Starting ARR × NRR) + (FY new-logo budget × capture ÷ cycle) + CS upsells + second-product contribution
Five inputs. Three of which behave very differently depending on what state the market is in. The trick is not in the formula — the formula is trivial. The trick is in admitting that three of those five inputs are not single numbers. They are conditional. They take different values in different market states. And you don't know in advance which market state you're going to get.
Regime parameters
| Parameter | Calm (5% prior) | Turbulent (55% prior) | Stormy (40% prior) |
|---|---|---|---|
| NRR — net revenue retention | 108% | 96% | 70% |
| Capture — % of new-logo budget closed | 95% | 65% | 40% |
| Cycle — sales-cycle multiplier vs 2022 | 1.0× | 1.3× | 1.65× |
Three of the five inputs to forward ARR behave differently depending on the market state. Turbulent multiplier calibrated to Optifai 2026 benchmark (+25% vs 2022, N=939). NRR and capture from N.Rich pipeline history.
The 1.3× Turbulent multiplier is calibrated to the published B2B SaaS benchmark for 2026 — roughly +25% sales-cycle elongation vs 2022 (Optifai, N=939). Stormy is the tail above that. NRR and capture are calibrated to our pipeline history under analogous conditions.
So when I run the formula under each regime for our specific numbers — €5.7M contracted base, €5.79M FY new-logo budget — I get:
Forward ARR by regime
| Component | Calm (5%) | Turbulent (55%) | Stormy (40%) |
|---|---|---|---|
| Retained ARR (base × NRR) | €6.16M | €5.47M | €3.99M |
| New logo (budget × capture ÷ cycle) | €5.50M | €2.90M | €1.40M |
| CS upsells | €1.30M | €0.90M | €0.50M |
| Second product | €1.00M | €0.50M | €0.50M |
| Total Forward ARR | €14.0M | €9.8M | €6.4M |
€5.7M contracted base, €5.79M FY new-logo budget. Three scenarios, one commit — how do you model for it?
Where the priors come from
The probabilities I attached to each regime — 5% Calm, 55% Turbulent, 40% Stormy — are not my opinion. I pulled them off the WEF Global Risks Report 2026, in which only 1% of 1,300+ surveyed global risk experts expect a calm two-year horizon and 50% expect turbulent or stormy conditions.
That's the macro view. McKinsey's March 2026 Global Survey puts geopolitical instability as the #1 growth risk for the first time since March 2022. The IMF's April 2026 World Economic Outlook is titled "Shadow of War."
When three independent global bodies converge on the same framing in three different vocabularies, you're not in a softening cycle. You're in a regime shift.
The honest move was to use those priors instead of my own. I have a structural bias to believe my pipeline will close. The IMF doesn't. The IMF is also right more often than I am about whether the world is about to get harder.
What the macro priors look like inside B2B SaaS
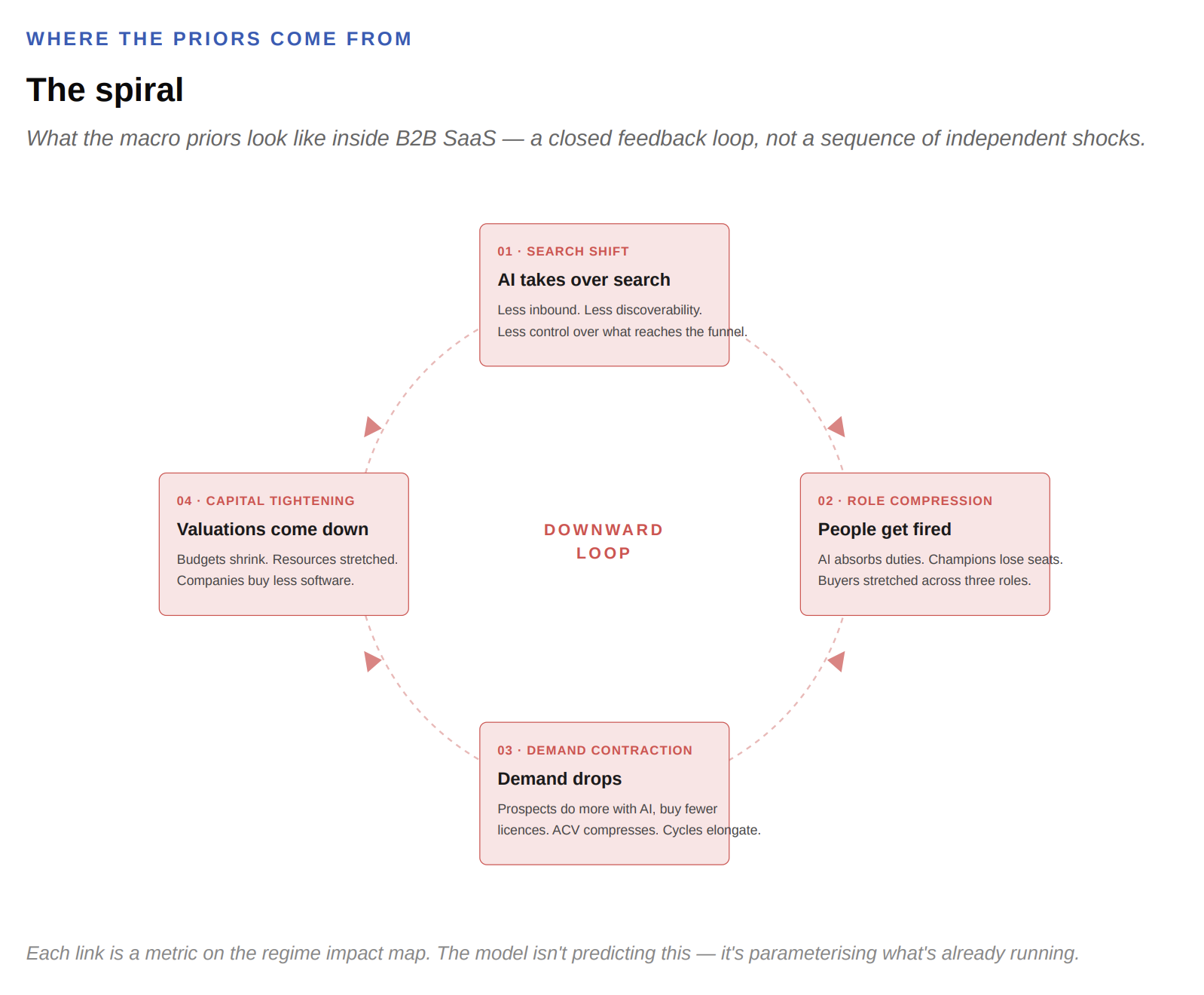
A closed feedback loop, not a sequence of independent shocks.
01 · Search shift — AI takes over search. Less inbound. Less discoverability. Less control over what reaches the funnel.
02 · Role compression — people get fired. AI absorbs duties. Champions lose seats. Buyers stretched across three roles.
03 · Demand contraction — demand drops. Prospects do more with AI, buy fewer licences. ACV compresses. Cycles elongate.
04 · Capital tightening — valuations come down. Budgets shrink. Resources stretched. Companies buy less software.
AI is taking over search. Less inbound. Less discoverability. Less of the kind of demand the standard funnel was built to capture, and less control over what reaches it. People are getting fired because AI takes over their duties, which means the buyer I sold to last year may not be in the seat next quarter, or may be there stretched across three roles instead of one. Champion stability collapses.
Demand drops because prospects do more with AI and buy fewer licences. The fifty-seat deployment becomes a thirty-seat deployment. The proof-of-concept never converts. ACV compresses. Cycles elongate. Valuations come down because budgets shrink and the strain on remaining resources is severe, which means companies buy less software. Which means fewer leads at the top. Which means more pressure to replace headcount with AI. Which closes the loop.
One qualification, since the diagram looks more closed than it really is. The loop doesn't form a clean four-link causal chain. AI dominance in search isn't caused by SaaS companies cutting their own headcount — it's driven by capability shifts at the model labs that are largely exogenous to anything individual SaaS companies do. So this is more honestly a web of mutual reinforcement than a closed loop: shared drivers, overlapping timing, correlated impact on the metrics a CRO is responsible for. The standard forecasting practice treats these forces as independent shocks. They aren't. That's the failure mode the diagram is meant to surface.
Each link in that loop is a metric on the regime impact map. Win rate, ACV, champion stability, cycle length, NRR. The regime model isn't predicting these things will happen. It's parameterising the loop that's already running.
So where does all of this leave the forecast?
Once you weight the three regime outcomes by the WEF-implied priors:
| Regime | Outcome | × Prior | = Contribution |
|---|---|---|---|
| Calm | €14.0M | 0.05 | €0.70M |
| Turbulent | €9.8M | 0.55 | €5.39M |
| Stormy | €6.4M | 0.40 | €2.56M |
| Probability-weighted central forecast | €8.6M |
That's the central forecast for 2026. Not €10M. Not €14M. €8.6M.
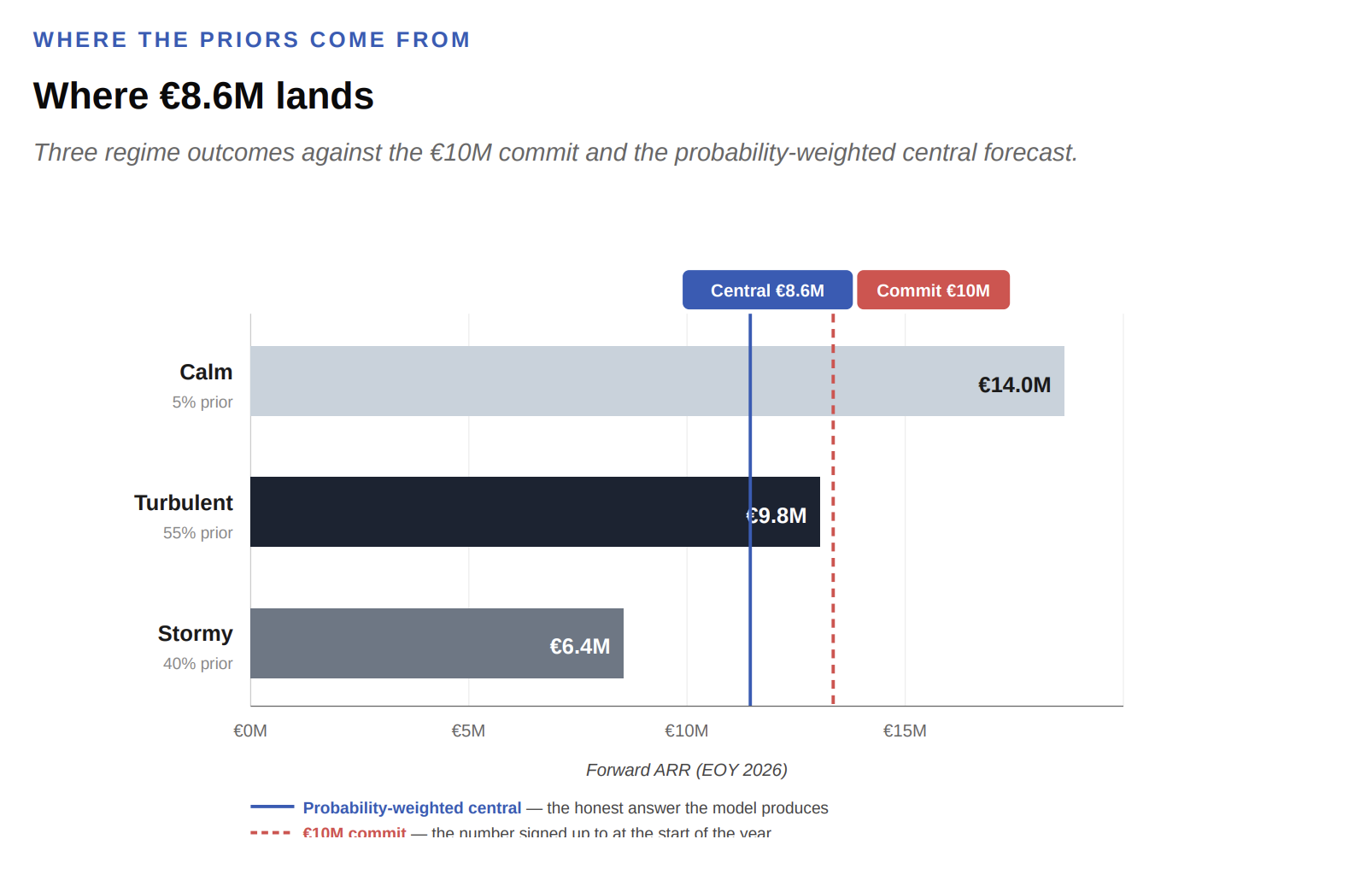
The €10M commit sits between the Turbulent outcome and the central forecast. The honest central is below the commit. That is the number I put in front of my board.
The two registers
Here is the part nobody told me when I started building this.
The most rigorous forecast is the wrong one to run the operation against. The number I just walked you through — €8.6M central, below our €10M commit — is correct for the board. It is professionally suicidal for the team.
Sellers do not sell a plan whose central forecast lands below commit. CSMs do not protect one. BDRs do not pick up the phone for one. The team needs a number to push against, not a distribution to interpret.
The mitigations are per-metric. Here's what one looks like in motion.
You don't mitigate "Turbulent." You mitigate the specific metric that Turbulent is hitting.
Look at the impact map again. Each metric in those amber and red cells has its own response. ACV compression wants pricing flexibility, not pricing defence. Logo churn wants behavioural-state CS, not binary at-risk flags. NRR collapse wants CS depth, not CS breadth. Champion stability wants seat-change monitoring as a leading indicator, not as an after-the-fact incident report. Sales cycle elongation wants pipeline-build timing to lead the quarter by one to two months more than it used to. Each one is a different lever, a different owner, and a different timeline.
I'm not going to walk you through all of them. The point of this piece isn't to give you my playbook — yours will differ. The point is to show what one mitigation looks like when you actually run it, and at what pace. So here's one.
The cluster: win rate and ACV
Under Turbulent, my regime-conditional model says win rate compresses by 25–35% and ACV compresses by 5–15%. Those are the two amber cells at the top of the impact map. The growth math is:
ARR Growth = New Acquisition + Expansion − Churn, where New Acquisition = Leads × (conversion through the funnel) × ACV
If win rate compresses, the conversion term drops. If ACV compresses, the ACV term drops. Two of the three multipliers in the New Acquisition equation are moving against you simultaneously. The only term you can move in the opposite direction is Leads — the top of the funnel. It is not a clever lever. It is the only lever. Either you increase TOFU volume to compensate, or the math breaks before the quarter is over.
So I went and looked at our actual funnel.
The mature-cohort averages from the last six quarters: SAL → SQL conversion 30.5%. SQL → SQO conversion 43%. SQO → Won under Turbulent assumptions 17%. End-to-end composite of SAL → Won: 7.4%.
The math on defending €5.5M of new-logo ARR at €175K ACV: 31 wins needed for the year. At Turbulent conversion that's 185 SQOs, 370 SQLs, 1,232 SALs. Current run-rate annualised: 530 SALs. The gap is +702 SALs. Roughly double.
The other thing the funnel data told me — and this is the part most CROs miss — is that SQLs and SQOs are almost where they need to be. The funnel below SAL is healthy. The entire gap is at the top. Pushing volume without a quality floor would compress SAL → SQL conversion and make the math worse, not better. So the ask had to be volume and quality, together. ~2× SAL flow, with SAL → SQL held at or above 30%.
I was running the math while being in constant communication with the CEO. Once the above logic surfaced, a meeting with Marketing was set.
The session was an hour. We walked through the historical data, the regime model, the impact map, the gap. I made the ask. Marketing pushed back on the volume number — fair — and we worked through the channel-mix conversation, which is where the answer actually lives. Channels with high SAL → SQL conversion (inbound, referrals, ABM-led outbound) get to grow faster than channels with low SAL → SQL conversion (paid social, broad outbound). Marketing committed to a quarterly cadence rather than a single annual ask, with a quality floor at 30% and a channel-level breakdown to follow within two weeks. We landed three commitments before we left the room.
That's the loop. Regime model surfaces the at-risk metric. ARR math identifies the lever. Funnel data sizes the ask. Working session lands the commitment. From regime read to committed mitigation: about three weeks. Most CROs run this on an annual planning cadence. The math doesn't survive an annual cadence.
And this is one cluster. There are six others on the impact map. Each one has its own version of this same loop running on its own timeline. The CS rebuild is running. The pricing-flexibility shift is running. The champion-stability monitoring is being instrumented. None of it is strategic theatre. All of it is metric-by-metric, owned, timed, measurable.
If your version of this loop isn't running, the question isn't whether you have a better mitigation strategy. The question is whether you have a CRO seat with the operating discipline the role now requires. Boards are going to start asking. The ones that already have are not waiting for next year's planning cycle to find out.
This is the level of detail. This is the level of ownership. This is the pace.
The regime framework, reframing the conversation
The regime framework wasn't just a planning artefact. It changed how we ran customer accounts in ways that no spreadsheet would have surfaced.
The most useful thing it gave us was a piece of cognitive shorthand I'd been carrying that turned out to be wrong: the assumption that risk is binary. A customer is either at risk or they're not. A deal is either alive or it's dead. A budget either holds or it doesn't.
It is none of those things. Every customer is in a regime, every account budget is in a regime, every champion's seat is in a regime. And those regimes shift independently.
Concrete example. A customer at €200K licence plus €600K of campaign spend looked healthy on paper. Their CFO came under pressure. The first thing they tried to cut was the campaign spend, not the licence. We almost flagged them as a churn risk and went into save-mode, which would have triggered the actual churn we were trying to prevent. The right move turned out to be the opposite: keep the licence, offer a "cruise mode" with containing the spend, hold the relationship through their stormy window, and resume scale when they came out the other side.
That insight is impossible inside a binary CS framework. It only shows up when you accept that customers have regimes too, and that the right response in one regime would be a mistake in another.
The same shift hit our sales motion. Most of our late-stage stalled deals weren't dying — they were paused because the buyer's career was under pressure. When the CMO at a prospect was three weeks away from a redundancy round, "buying ABM software" was not on their list. "Surviving the next quarter" was. Our sellers were getting nowhere because they were selling a 2024 product into a 2026 buyer mindset.
What worked was reframing the conversation. Acknowledge the pressure directly. Stop pitching the platform. Start asking what their personal Q3 looked like. What would they need to walk into their board meeting with? How could we help them get there? The deals didn't move because we got better at product positioning. They moved because we stopped pretending the buyer wasn't a person trying to keep their job in a market that was deleting jobs.
Both moves — the cruise-mode for customers, the personal-KPI lens for prospects — flow from the same insight. The regime model isn't a forecasting tool. It is a way of seeing. And the seeing only happens if you are close enough to the customer and the buyer to interpret what the model is telling you.
Which is the cleanest argument I can make for why the CRO does this work, not the CFO. A 1.3× cycle elongation is a number to a CFO. To a CRO who was in the customer's office last week, it is a named buyer asking for a six-month contract because their CFO is six weeks from a budget cut. A 70% NRR floor in Stormy is a parameter on a slide. To a CRO who knows the champion at that account, it is the recognition that her seat is going away and we should be moving the relationship before it does.
Commercial interpretation requires commercial context. Commercial context lives in the CRO seat. Therefore the interpretation has to live there too.
What I did wrong
I was operating the "wrong" model for at least two quarters before I noticed.
When I first ran the recalibrated regime-weighted model and saw the central forecast land below commit — from a number well clear of €10M to €8.6M — my instinct was to look for the bug. There must be something wrong with the priors. Or the within-regime variance. Or my capture-rate assumption was too harsh. Some part of me wanted the answer to be "actually we're fine, the model is broken."
The priors were defensible. The math was right. The capture rates were calibrated to what I was already seeing in pipeline. The model wasn't broken. The prior model had been broken, and I'd been running my plan on it.
Writing this down is the cost of doing the analysis honestly. If you build a regime-weighted forecast, you have to accept that the first time you run it correctly, the number will be worse than the one you've been using. There is no path to intellectual rigour that doesn't pass through admitting that you were wrong about something the board has already heard you say.
The version of this I see most CROs running is the gentler one: "I'm running a more conservative scenario now" or "I'm adding downside cases." That is not the same thing.
Adding downside cases on top of an optimistic base model just gives you more decimal places. Replacing the base with regime-weighted probabilities means accepting that your central forecast is lower than the one you committed to last quarter. Most CROs don't, because the alternative is sitting across from a board and saying "the number I gave you in January is no longer the number."
That conversation is uncomfortable. It is also the conversation that protects you. The board penalises CROs who don't have it. They don't always penalise CROs who do.
The CRO role is changing. Most CROs haven't noticed.
I've had a few peers describe what I just walked you through as atypical for the CRO role. The implication is that this is the CFO's job — that data, modelling, macro priors, and forecasting rigour belong with finance, and the CRO should be focused on hitting the number that comes out the other end.
I don't think that's right.
Closing
I built this in response to a problem I was sitting with, not a framework I'd read. The macro-prior anchoring on WEF / IMF / McKinsey, the regime parameterisation, the per-metric mitigation playbook, the board-vs-operating register distinction — they emerged from trying to reconcile a forecast I didn't believe with a board I owed an honest answer to. I built what I needed.
The contribution here, if there is one, is the operator's account of using this under real stakes. Of standing in front of a board and committing to a number that sits above where the central forecast lands. Of running an operation against a different number than the one I was forecasting. Of going to Marketing with a 2× SAL ask and being able to defend it from first principles. Of accepting that the price of intellectual honesty in this seat is carrying two stories at once and not confusing them.
The honest CRO's job in 2026 is not to forecast the year correctly. It is to build a plan that survives being wrong — and to do the work that makes the plan worth defending. Not the work the role used to require. The work the role requires now.
That is what I'm trying to do.
Written from inside the seat about what the role requires in 2026 and beyond. The frameworks are rigorous. The examples are current. The voice is what you'd hear at a board dinner with no PR person in the room.